引言
在机器学习中,回归模型是一类广泛使用的模型,用于对数值型、连续型变量进行预测,例如房价、温度或股票价值。传统的回归模型由精确的参数或权重定义,并且通常假设这些估计值没有不确定性。贝叶斯回归的引入是为了以概率方式模拟预测变量和目标变量之间的关系,从而将不确定性引入建模过程。
传统回归模型
传统回归模型以估计值 ˆ𝑦 的形式对目标连续变量(例如房价)进行预测,该估计值是一个单一的、确定的值,例如,对于输入了模型属性的房屋,其估计价格。例如,具有 n 个输入变量(例如房屋属性)的线性回归模型的方程由以下线性方程给出:
其中 𝜖 是误差项, 𝛽0,…,𝛽𝑛 是与输入变量相关的权重,再加上一个偏置项 𝛽0 。将此方程应用于特定学习模型以预测房价的实际示例可能如下所示:
其中:
- 𝑥1 是房屋的面积(平方米)。
- 𝑥2 是卧室的数量。
- 𝑥3 是房屋的年龄(以年为单位)——请注意此特征的权重为负数,这意味着较旧的房屋会预测出较低的价格。这很有道理,因为较旧的房屋通常价格较低。
上述模型中的 50000、150、10000 和 -2000 值是其参数值或权重。这一点很重要,请记住。
贝叶斯回归是如何工作的?
那么,贝叶斯回归与此有何不同?与传统的回归不同,后者返回单个值作为预测估计,并且权重也学习为精确值,贝叶斯回归模型处理的是可能参数值的概率分布,从而考虑了预测中的不确定性。换句话说,在贝叶斯回归模型中,每个权重 𝛽𝑖 都变成了一个具有相关概率分布的随机变量。
学习过程也随之调整:我们不再寻求一组单一的“最佳拟合”权重 𝛽0,𝛽1,𝛽2,…,𝛽𝑛 ,而是尝试在给定训练数据(一组具有已知输出或目标值的实例)的情况下,找到参数的后验分布。
重要的是,由于权重被建模为分布,因此由此产生的预测 ˆ𝑦 也成为分布,而不是清晰的、单点的估计。因此,预测变得不确定。
为什么我们会对不确定而非精确的预测感兴趣?
在理解和考虑不确定性与进行预测本身同等重要的场景中,贝叶斯回归是有意义的。例如,在医疗诊断等高风险场景中,我们不仅想知道模型的预测是什么,还想知道模型对该预测有多自信或不确定。在置信度较低的情况下,医护人员可以运用他们的专业判断来解读结果。贝叶斯回归具有实际价值的其他场景包括自动驾驶汽车和金融预测:在这些情况下,基于可能错误的精确预测做出决策可能会带来高昂的成本或危险的后果;因此,将预测建模为概率分布是一种更具信息量的方法,可以平衡潜在风险或在必要时寻求额外信息。
贝叶斯回归:一个简单的例子
让我们通过一个非常简单的例子来理解贝叶斯回归是如何工作的。
假设我们想仅根据一个属性来估算房屋的价格:它的面积。输入属性用 𝑥1 表示。该问题的经典回归模型看起来会是这样的:
ˆ𝑦 =50000 +150 ⋅𝑥1
在贝叶斯回归中,两个模型权重 𝛽0 和 𝛽1 不会取像 50000 和 150 这样的精确值,而是作为概率分布进行学习。例如:
- 偏差项(也称为截距) 𝛽0 服从正态分布,即:
𝛽0 ∼𝑁(50000,50002)
- 同时,与单个输入特征 𝛽1 相伴的斜率或权重也服从正态分布,即:
𝛽1 ∼𝑁(150,202)
回想一下,定义正态分布的两个参数是其均值和方差。
那么,房价是如何预测的呢?模型不是返回一个单一的房价预测值,而是通过从与权重相关的这两个分布中进行采样来进行推断,从而产生一系列可能的预测值。例如,对于一栋 100 平方米的房子,两个样本可能看起来是这样的:
- 样本 1: 𝛽0 =52000 , 𝛽1 =160 ,价格为 ˆ𝑦 =52000 +160 ⋅100 =68,000 美元
- 样本 2: 𝛽0 =49000 , 𝛽1 =140 ,价格为 ˆ𝑦 =49000 +140 ⋅100 =63,000 美元
通过大量采样,我们最终会得到一个预测价格的分布,其中某些价格区间出现的频率会比其他区间高,因此,其概率也比其他区间高。基于此,我们可以将预测表述为置信区间,例如:
这栋房子的预测值为 65,500 美元,95% 的置信区间在 61,000 美元到 70,000 美元之间。
如前所述,在某些实际用例中,这些不确定的预测在有效和明智的决策制定中更有价值和帮助。
在 Python 中使用 Scikit-learn 进行贝叶斯回归
幸运的是,使用 scikit-learn 在 Python 中实现贝叶斯回归非常简单。
linear_model 模块提供了一个 BayesianRidge 对象,可用于执行贝叶斯回归。此对象与其他 scikit-learn 模型的工作方式类似:您创建一个模型实例,将其拟合到训练数据,然后使用它进行预测。然而,一个关键的区别是,当您调用 predict 方法时,您还可以请求预测的标准差,这为您提供了模型不确定性的度量。下面是一个简单的代码示例,演示了如何使用
BayesianRidge 将模型拟合到一些样本数据,然后进行预测,包括不确定性。Output:
在上面的代码中:
alpha_1:通过影响模型的权重,设定我们最初对输入和输出之间关系简单或复杂程度的假设
alpha_2:与alpha_1一起控制模型在多大程度上坚持其关于关系简单性的初始假设,而不是从数据中学习。
lambda_1:设定我们关于正在训练的数据中存在多少“噪声”或随机误差的初始假设。
lambda_2:用于控制模型在多大程度上坚持其关于噪声水平的初始假设。
下面的可视化展示了训练数据中的噪声、最佳拟合线,以及最重要的是,当我们远离训练数据点时,不确定性区间如何扩大,尤其是在外推时。这直观地展示了贝叶斯回归的核心优势:量化预测不确定性的能力。
以及我们生成的可视化图:
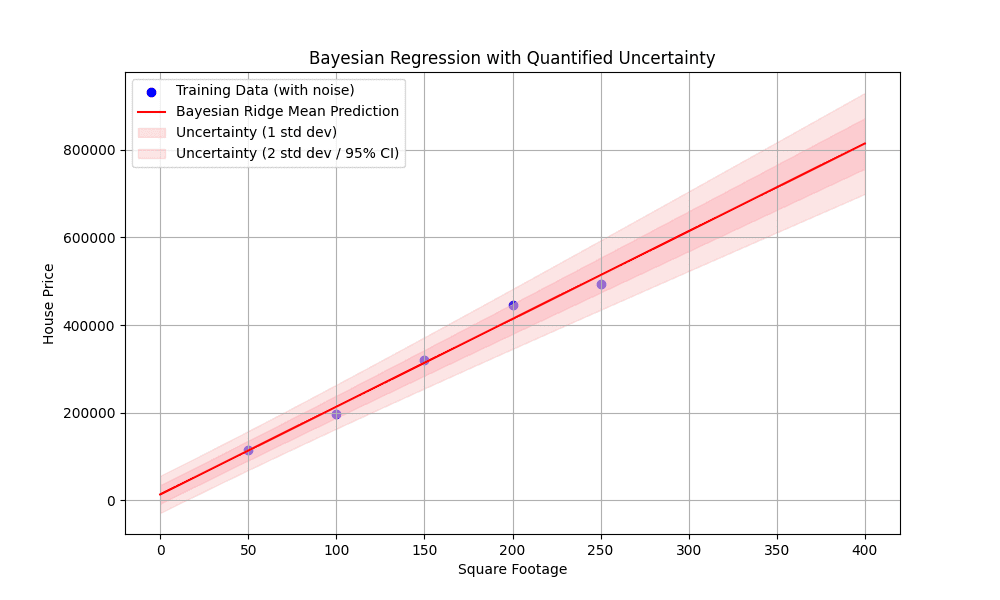
图 1:具有量化不确定性的贝叶斯回归
结语
贝叶斯回归可以看作是经典回归模型的、不确定且概率性的对应模型,而经典回归模型是机器学习模型中最广泛的类型之一,用于在许多实际应用中进行预测。本文对这种回归技术的基础知识及其有用性进行了初步介绍。
对特定的贝叶斯回归技术和模型感兴趣吗?在最受欢迎的模型中,我们有贝叶斯线性回归、贝叶斯岭回归和高斯过程回归(GPR)。