逻辑回归算法解析
虽然名字中带有"回归"二字,但逻辑回归实际上是一种专门用于分类任务的监督式学习算法,而非传统意义上的回归分析。该算法主要预测具有两种可能结果的二元分类目标变量。这些结果通常采用二进制数值表示(比如0或1、对或错、是或否等形式)。
举个栗子,逻辑回归能够判断某封邮件是否为垃圾邮件,或者预测用户是否会点击某个广告。该算法运用逻辑函数对目标变量归属于特定类别的概率进行建模,这个函数能将输入特征映射为0到1区间内的数值。
分类任务的本质探讨
在深入探究逻辑回归之前,咱们先搞清楚机器学习领域中分类的真正含义。分类是监督学习的一种形式,其目标是将数据点分配到特定的类别或组别中。与预测连续数值的回归任务不同,分类预测的是离散的标签。
分类问题的典型案例包括:
- 识别欺诈交易(欺诈或正常交易)
- 动物图片识别(猫咪、狗狗等)
- 基于患者症状进行疾病诊断(患病或健康)
在这些场景中,我们期望的输出都是一个类别标签。
逻辑回归的运作机制
与输出连续数值的线性回归不同,逻辑回归输出的是0到1区间内的概率得分。这个得分表示输入样本属于正类(通常用'1'表示)的可能性大小。
为了实现这个目标,算法采用了sigmoid函数,该函数能将任意输入值(特征的线性组合)映射到0到1范围内的某个数值。这个函数引入了非线性特性,让模型能够捕捉特征与结果概率之间的复杂关联。
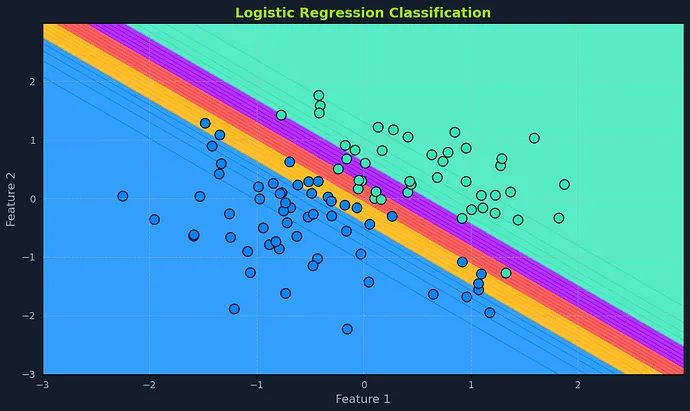
Sigmoid函数详解
Graph of sigmoid function showing an S-shaped curve with input (x) on the horizontal axis and output (y) on the vertical axis
Sigmoid函数是一个数学函数,它能将任何输入值(范围从负无穷到正无穷)转换为0到1之间的输出值。正因为这个特性,它在概率建模方面特别给力。
Sigmoid函数具有独特的"S"形曲线,因此得名。函数开始时对于负输入值较低,然后在零点附近快速攀升,最后在正输入值较高时逐渐趋于平稳。这种在0和1之间的平滑、渐进式过渡让它能够完美表示事件发生的概率。
在逻辑回归算法中,sigmoid函数将输入特征的线性组合转化为概率得分。这个得分代表输入样本属于正类的可能性。
Sigmoid函数的数学表达
Sigmoid函数的数学公式是:
- P(x)表示预测概率
- e是自然对数的底数(大约等于2.718)
- z是输入特征及其权重的线性组合,类似于线性回归方程:z = m1x1 + m2x2 + … + mnxn + c
垃圾邮件过滤实例
假设我们正在使用逻辑回归构建一个垃圾邮件过滤系统。该算法会分析邮件的各种特征,比如发送者地址、特定关键词的出现以及邮件内容等,从而计算出一个概率得分。如果得分超过预设的阈值(例如0.8),那么这封邮件就会被标记为垃圾邮件。
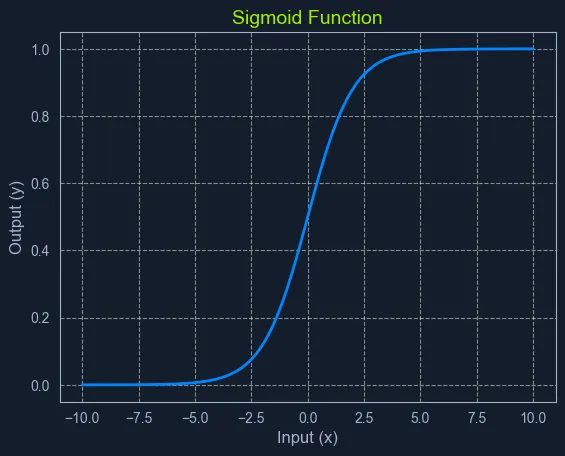
决策边界概念
Scatter plot with logistic regression decision boundary, showing data points classified as Class 0 and Class 1, with color-coded regions
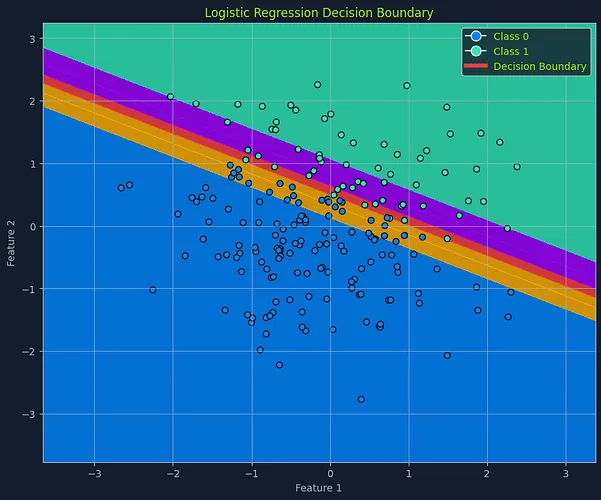
逻辑回归的一个核心特性是决策边界。在包含两个特征的简化场景中,可以想象有一条直线将数据点分成两个类别。这条分隔线就是决策边界,它由模型学习到的参数和选定的阈值概率共同决定。
在具有更多特征的高维空间中,这个分隔线会演变成一个超平面。决策边界定义了将某个实例划分到一个类别或另一个类别的临界点。
超平面概念解析
Scatter plot with hyperplane dividing Class 1 and Class 2 data points, labeled 'Hyperplane as a Decision Boundary
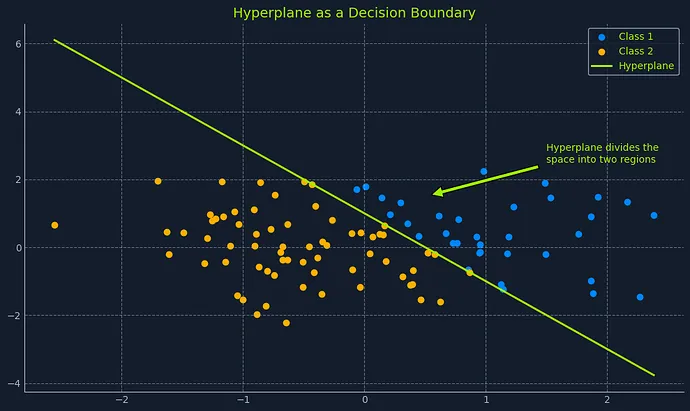
在机器学习领域中,超平面是一个子空间,其维度比周围环境空间的维度少一个。这是在高维度中可视化决策边界的一种方式。
可以这样理解:
- 在二维空间(比如一张纸)中,超平面是一条直线,它把空间分成两个区域
- 在三维空间(比如你的房间)中,超平面是一个平面,它将空间一分为二
当维度更高(超过三个特征)时,可视化变得困难,但概念保持一致。超平面是一个"平面"子空间,它将高维空间划分为两个区域。
在逻辑回归中,超平面由模型学习到的参数(系数)和选择的阈值概率定义。它充当决策边界的角色,根据预测概率将数据点归类到不同类别中。
阈值概率设置
阈值概率通常设为0.5,但也可以根据具体问题以及真假阳性之间的平衡进行调整。
- 如果给定数据点的预测概率P(x)高于阈值,该实例就被归类为正类
- 如果P(x)低于阈值,则被归为负类
例如,在垃圾邮件检测中,如果模型预测某封邮件有0.8的概率是垃圾邮件(阈值设为0.5),那么这封邮件就会被归类为垃圾邮件。如果将阈值调整到0.6,就需要更高的概率才能将邮件分类为垃圾邮件。
数据前提假设
逻辑回归虽然没有线性回归那么严格,但对数据仍有一些基本假设:
- 二元结果:目标变量必须是分类变量,只能有两种可能的结果
- 对数几率的线性关系:算法假设预测变量与结果的对数几率之间存在线性关系。对数几率是概率的一种变换,表示几率比(事件发生概率除以不发生概率)的对数
- 没有或极少多重共线性:理想情况下,预测变量之间应该几乎没有多重共线性。多重共线性出现在预测变量高度相关时,这会让人难以确定它们对结果的单独影响
- 大样本容量:逻辑回归在较大的数据集上表现更佳,能够进行更可靠的参数估算
在应用逻辑回归前评估这些假设有助于确保模型的准确性和可靠性。可以使用数据探索、可视化和统计检验等技术来评估这些假设。
决策树算法详解
决策树是一种备受欢迎的监督学习算法,既适用于分类任务也适用于回归任务。决策树以其直观的树状结构而闻名,这让它们变得容易理解和解释。从根本上说,决策树构建了一个模型,通过学习从数据特征中推导出的简单决策规则来预测目标变量的取值。
设想一下,你正试图根据天气状况决定是否去打网球。决策树会将这个决定拆解成一连串简单的问题:今天天气晴朗吗?有风吗?湿度高吗?基于这些问题的答案,决策树会引导你做出最终决策:打网球还是不打网球。
决策树由三个主要组成部分构成:
- 根节点:代表树的起始点,包含完整的数据集
- 内部节点:这些节点表示数据的特征或属性。每个内部节点根据不同的决策规则分成两个或更多子节点
- 叶节点:这些是树的终端节点,代表最终的结果或预测
决策树构建过程
构建决策树需要在每个节点上选择最优特征来分割数据。这种选择基于基尼不纯度、熵或信息增益等指标,它们量化了分割后产生的子集的同质性。目标是创造能产生越来越纯净子集的分割,其中每个子集中的数据点主要属于同一类别。
基尼不纯度/基尼指数
基尼不纯度测量从集合中随机选择一个元素被错误分类的概率。基尼不纯度越低,意味着集合越纯净。基尼不纯度的计算公式为:
- S是数据集
- pi是属于第i个类别的元素在集合中所占的比例
考虑一个包含两个类别:A和B的数据集S。假设数据集中有30个属于类别A的实例和20个属于类别B的实例。
- A类的比例:pA = 30 / (30 + 20) = 0.6
- B类的比例:pB = 20 / (30 + 20) = 0.4
该数据集的基尼不纯度为:
熵值计算
熵表示集合的混乱程度或不确定性。熵越小,意味着集合越均匀。熵的计算公式为:
- S是数据集
- pi是属于第i个类别的元素在集合中所占的比例
使用相同的数据集S,包含30个属于类别A的实例和20个属于类别B的实例:
- A类的比例:pA = 0.6
- B类的比例:pB = 0.4
该数据集的熵值为:
信息增益
信息增益用来度量根据特定特征分割数据集所实现的熵减少量。分割时会选择信息增益最大的特征。信息增益的计算公式为:
- S是数据集
- A是用于分割的特征
- Sv是特征A具有值v的S的子集
考虑一个包含50个实例的数据集S,其中有两个类别:A和B。假设我们考虑的特征F可以有两个值:1和2。数据集的分布如下:
- 对于F = 1:30个实例,20个A类,10个B类
- 对于F = 2:20个实例,10个A类,10个B类
首先,计算整个数据集S的熵:
接下来,计算每个子集Sv的熵:
- 对于F = 1:
- A类的比例:pA = 20/30 = 0.6667
- B类的比例:pB = 10/30 = 0.3333
- Entropy(S1) = (0.6667 log2(0.6667) + 0.3333 log2(0.3333)) = 0.9183
- 对于F = 2:
- A类的比例:pA = 10/20 = 0.5
- B类的比例:pB = 10/20 = 0.5
- Entropy(S2) = (0.5 log2(0.5) + 0.5 log2(0.5)) = 1.0
现在,计算子集的加权平均熵:
最后,计算信息增益:
树的构建流程
树从根节点开始,根据某一个标准(基尼不纯度、熵或信息增益)选择最能分割数据的特征。该特征成为内部节点,并为该特征的每个可能值或值范围创建分支。然后根据这些分支将数据划分为子集。这个过程对每个子集进行递归操作,直到满足停止条件。
当满足以下条件之一时,树就停止生长:
- 最大深度:树达到指定的最大深度,防止树变得过于复杂并可能过度拟合数据
- 最小数据点数:节点中的数据点数低于指定阈值,确保分割是有意义的,而不是基于很小的子集
- 纯净节点:节点中的所有数据点都属于同一类别,表明进一步分割不会提高子集的纯度
实例分析:网球运动决策
让我们深入研究"打网球"的例子,来说明决策树在实际应用中是如何运作的。
想象你有一个数据集,包含历史天气条件以及你是否在这些日子里打网球。例如:
PlayTennis | Outlook_Overcast | Outlook_Rainy | Outlook_Sunny | Temperature_Cool | Temperature_Hot | Temperature_Mild | Humidity_High | Humidity_Normal | Wind_Strong | Wind_Weak |
No | False | True | False | True | False | False | False | True | False | True |
Yes | False | False | True | False | True | False | False | True | False | True |
No | False | True | False | True | False | False | True | False | True | False |
No | False | True | False | False | True | False | True | False | False | True |
Yes | False | False | True | False | False | True | False | True | False | True |
Yes | False | False | True | False | True | False | False | True | False | True |
No | False | True | False | False | True | False | True | False | True | False |
Yes | True | False | False | True | False | False | True | False | False | True |
No | False | True | False | False | True | False | False | True | True | False |
No | False | True | False | False | True | False | True | False | True | False |
数据集包含以下特征:
- 天气状况:Sunny(晴天)、Overcast(阴天)、Rainy(雨天)
- 温度:Hot(炎热)、Mild(温和)、Cool(凉爽)
- 湿度:High(高湿度)、Normal(正常湿度)
- 风力:Weak(微风)、Strong(强风)
目标变量是打网球:Yes或No。
决策树算法会对该数据集进行分析,识别最能将"Yes"实例与"No"实例区分开的特征。首先,它会计算每个特征的信息增益或基尼不纯度,以确定哪个特征能提供最有信息价值的分割。
决策树算法会分析这个数据集来识别最佳特征,这些特征可以将"是"与"否"有效分离。它首先会计算每个特征的信息增益或基尼不纯度,以确定哪个特征能够提供最有信息量的分割。
例如,算法可能发现天气状况特征提供了最高的信息增益。这意味着根据晴天、阴天或雨天对数据进行分割,能够最显著地减少熵或不纯度。
决策树的根节点将是天气状况特征,并有三个分支:晴天、阴天和雨天。基于这些分支,数据集被分为三个子集。
接下来,算法会分析每个子集,确定下一次分割的最佳特征。例如,在"晴天"子集中,湿度可能提供最高的信息增益。这将产生另一个具有"高湿度"和"正常湿度"分支的内部节点。
这个过程会递归进行,直到满足停止条件,如达到最大深度或节点中数据点的最小数量。最终结果是一个树状结构,每个内部节点都有决策规则,叶节点则有预测结果(打网球:Yes或No)。
数据假设条件
决策树的优势之一是对数据的假设要求最少:
- 无线性假设:决策树能够处理特征与目标变量之间的线性和非线性关系。这使得决策树比线性回归等假设线性关系的算法更加灵活
- 无正态性假设:数据不需要服从正态分布。这与某些需要正态性才能做出有效推断的统计方法形成了鲜明对比
- 异常值处理:决策树对异常值的处理相对鲁棒。由于决策树是基于特征值对数据进行分区,而不是依赖于基于距离的计算,因此异常值不太可能对决策树结构产生重大影响
这些最小化的假设条件增强了决策树的多功能性,使其能够无需大量预处理或转换就应用于各种数据集和问题。就像早期TensorFlow图像识别模型那样,在实际应用中展现出强大的适应性。