Q-学习(Q-learning):用试错把“哪步最值”给学出来
Q-learning 是一种典型的“无模型”强化学习套路:不提前建环境模型,直接上手和环境过招,靠观察反馈把每个“状态-动作”组合的收益(Q 值)估出来。Q 值可以理解为:当前看到某个状态时,执行某个动作、随后继续按最优策略走下去,长期累计能拿到多大的回报。
脑补一个场景:一辆新手上路的自动驾驶车,刚进城啥也不懂,红绿灯、人行道、路口规则一概陌生。用 Q-learning,它就像“开盲盒”一样不断尝试,加速、刹车、左拐、右拐,系统给它“奖励或惩罚”(安全高效抵达目的地就加分,违规或剐蹭就扣分)。时间一长,它自然就摸清哪种情况下做什么操作更“真香”,最后把城市驾驶玩得明明白白。

Q-Table:像一本“动作攻略字典”
Q-learning 的核心是 Q-Table。它就像一个查表手册,横向是动作,纵向是状态,每个格子里是一对“状态-动作”的 Q 值,用来指导智能体做选择。比如自动驾驶的不同路口或路段是不同“状态”,动作是“加速、减速、左转、右转”等,表格里的数值越大,说明在该状态下做这个动作越划算。
以下是一个“网格世界”的极简示例:机器人能向上、下、左、右移动,网格每个位置都是一个“状态”。
State/Action | Up | Down | Left | Right |
S1 | -1.0 | 0.0 | -0.5 | 0.2 |
S2 | 0.0 | 1.0 | 0.0 | -0.3 |
S3 | 0.5 | -0.5 | 1.0 | 0.0 |
S4 | -0.2 | 0.0 | -0.3 | 1.0 |
在这张表里,S1 到 S4 是不同状态,四个方向是可选动作,格子里的数字就是“在该状态执行该动作”的当前估计收益(Q 值)。学习过程中,这些数值会持续被刷得更准。
Q 值的更新遵循 Q-learning 的经典更新式,源自贝尔曼最优性思想:
- Q(s, a):在状态 s 做动作 a 的当前估计值
- α(学习率):新信息占比,越大越“敢改”
- r:这步动作后立刻拿到的奖励
- γ(折扣因子):看未来回报的“耐心值”,越大越看长远
- max(Q(s', a')):下一状态 s' 所有动作里最能打的那个 Q 值
来一条具体更新的小案例(沿用上方表的设定):
- 机器人现在在 S1
- 它选了 Right,跳转到 S2
- 这一步给了它 r = 0.5 的奖励
- 学习率 α = 0.1,折扣 γ = 0.9
- 下一状态 S2 的“最佳选项值”是 max(Q(S2, ·)) = max(0.0, 1.0, 0.0, -0.3) = 1.0
把数代进去:
也就是说,经历了这次“尝试→反馈”后,S1 执行 Right 的性价比从 0.2 升到了 0.32,说明它学到了一丢丢有用的信息。
Q-Learning 算法流程:循环三件事,直到学会为止
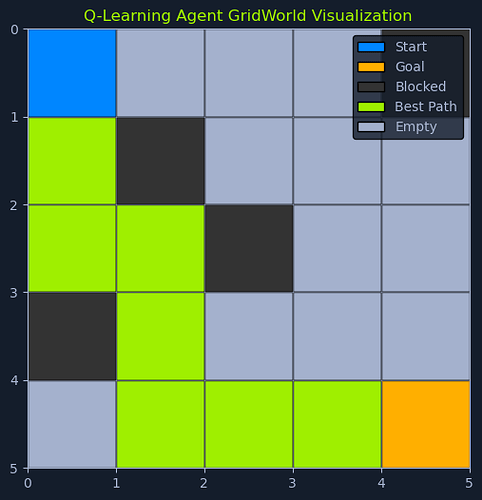
一个 5×5 GridWorld 的示意:起点在 (0,0),终点在 (4,4),部分格子为障碍,绿色路径为学到的最优路线
Q-learning 的日常就是“选动作→执行观察→更新 Q 值”的反复横跳。与环境越多互动,它对“该怎么做最划算”的判断就越靠谱。
标准步骤可以拆成:
- 初始化:造一张 Q-Table,通常全零开局,也可以塞点先验常识。后续学习会不断把它打磨精细。
- 行动选择:在当前状态下挑一个动作。这里的灵魂是“探索”与“利用”的平衡:是大胆试新路,还是稳妥走老路?
- 执行动作并观测:做了动作之后,记录新状态和即时奖励,这些是一手反馈数据。
- 更新 Q 值:用上面的更新式,把“这次经历”折算进对应的状态-动作格子里。
- 切换状态:把当前状态设置为刚到达的新状态,准备下一轮。
- 反复迭代:一直循环到 Q 值基本稳定,或者达到设定的迭代上限、时间上限等停止条件。
当 Q-Table 被练到位,智能体就会“沿着回报最大化”的路径从起点稳稳走到目标,几乎不怎么踩雷。
探索 vs 利用:怎么拿捏分寸
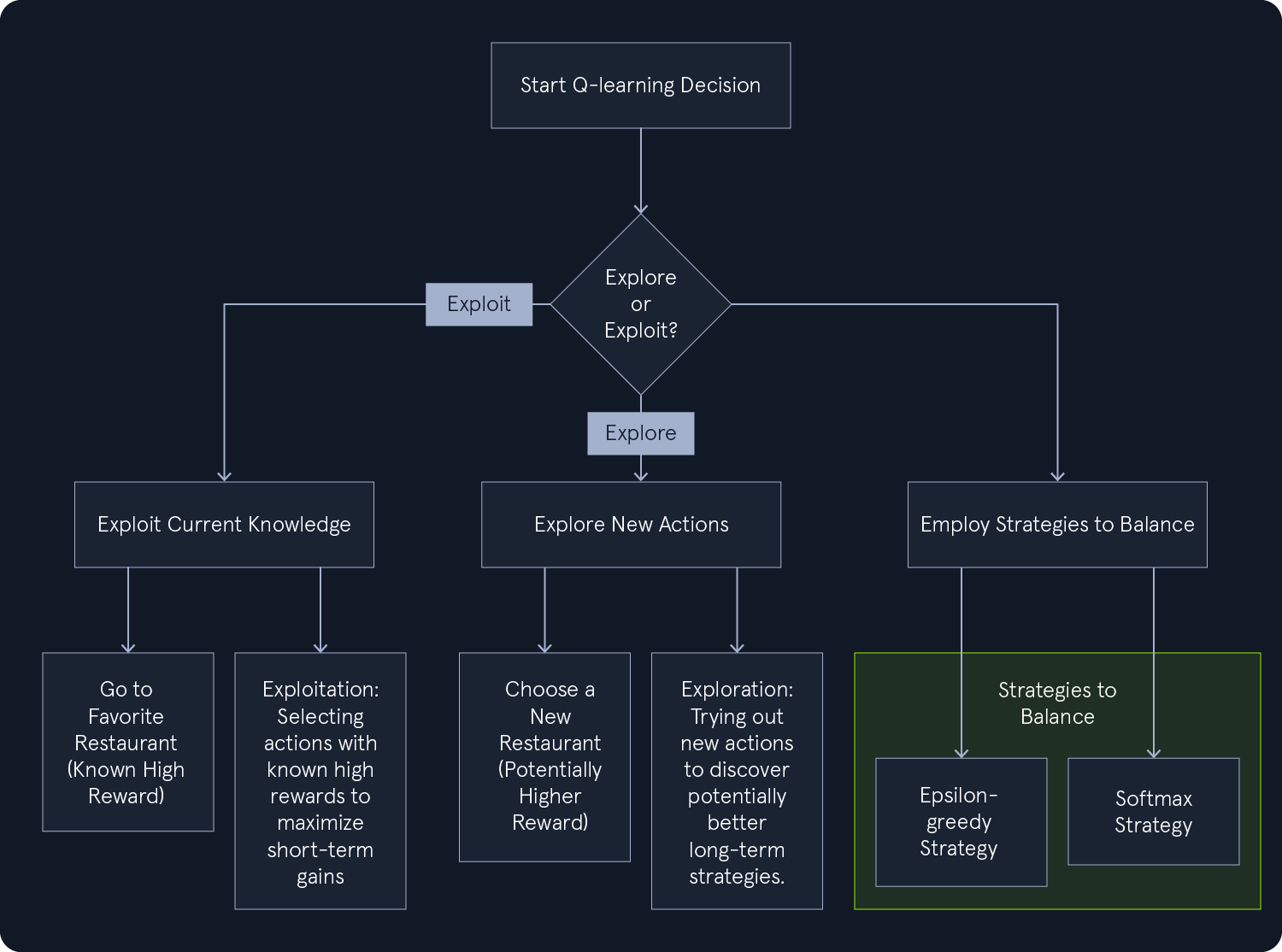
在 Q-learning 里,最常见的纠结就是:要不要尝鲜?
- 利用:押注已经验证过的高回报操作,短期收益稳。
- 探索:偶尔“开开新图”,也许能挖到更香的策略,不至于被早期经验“框死”。
打个生活类比:挑餐馆吃饭。去常去的那家十拿九稳,但偶尔换家新店,没准遇到“隐藏菜单”,直接封神。
ε-贪婪(epsilon-greedy):简单好用的平衡术
epsilon-greedy 在动作选择里掺入一点点随机。用概率 ε 去“随个缘”(探索),用概率 1-ε 选当前最优(利用),既避免“死磕老路”,又不至于“瞎闯过头”。
- ε 高(比如 0.9):初来乍到,先多见见世面,广撒网多试错。
- ε 低(比如 0.1):越到后期越稳重,主打熟练路线,偶尔小小尝新。
实际训练里,常见做法是“退火式”降低 ε:前期一把子探索,后期慢慢收敛到利用为主,这样学得又快又不易被局部最优拿捏。
数据与环境假设
Q-learning 对前提要求不多,但有两条底线:
- 马尔可夫性:未来状态只依赖“当前状态 + 当前动作”,不看更久远的历史。
- 环境相对静态:转移概率和奖励机制在训练期间不要花式变形。
朴素但抗揍,能打的通用解法
Q-learning 不用环境模型,靠交互把“值”学出来,适合动态复杂、规则难写全的场景。只要把探索与利用拿捏好、学习率与折扣系数调教合适,它就能在一轮又一轮的试错中,把策略越练越顺手,最后把长期回报拉满。