生成式人工智能
生成式人工智能(Generative AI)是机器学习中一个让人疯狂且发展迅速的领域,其重点是输出类似于人类生成的新内容或数据。与旨在识别模式、分类数据或进行预测的传统人工智能系统不同, 生成式人工智能侧重于生成原创内容,从文本和图像到音乐和代码。已经成为了现实:一位艺术家利用自己的技能和想象力创作出一幅画。同样,
生成式人工智能模型利用其学习到的知识来生成新的和创造性的输出,会表现出惊人的独创性和逼真性。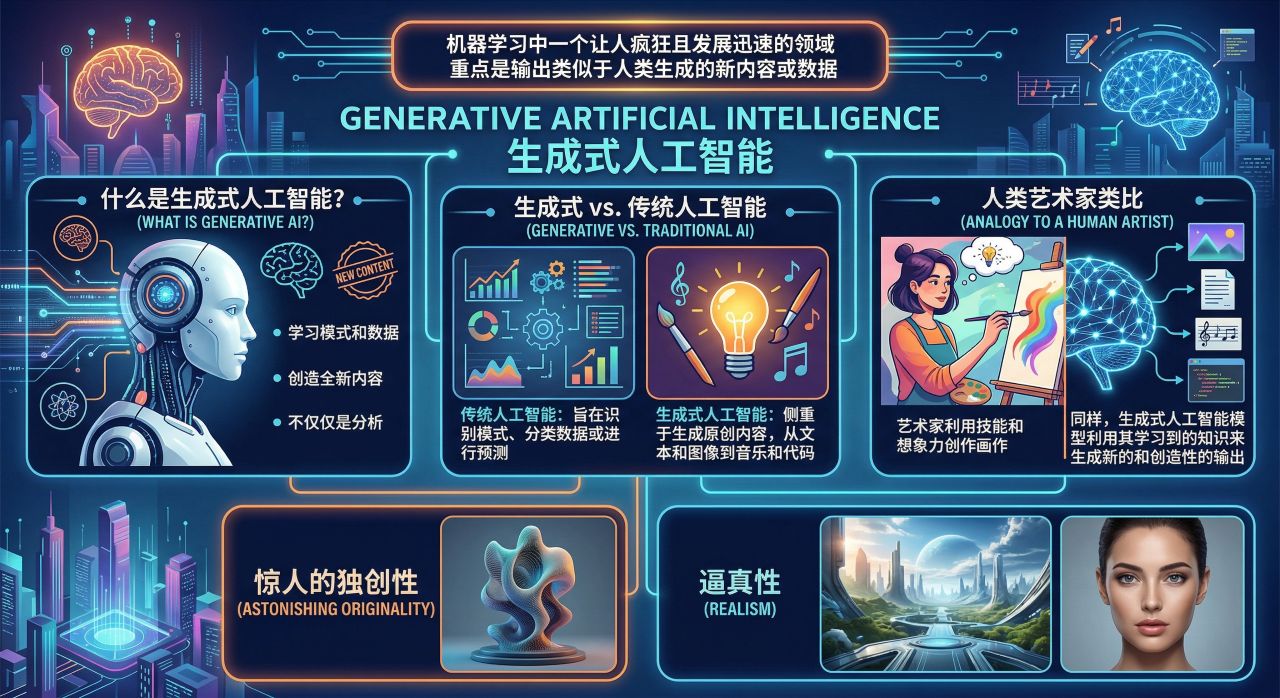
生成式人工智能如何工作
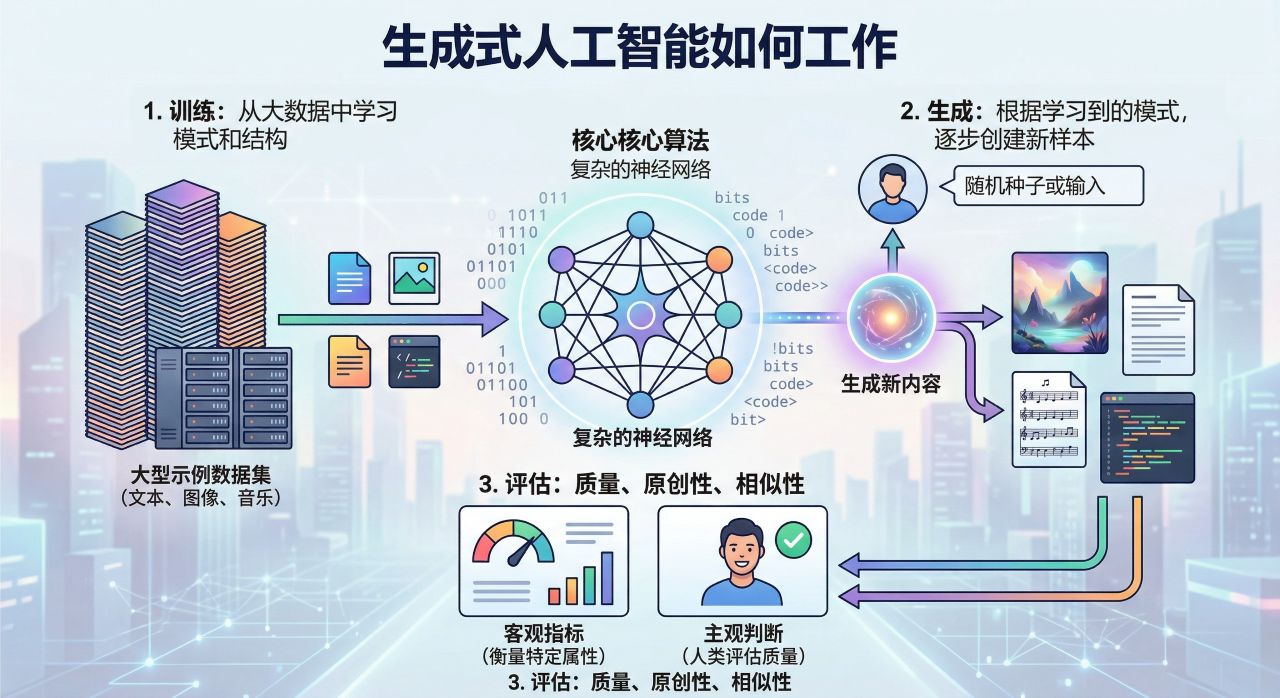
生成式人工智能的核心是复杂的算法,通常基于神经网络,可学习给定数据集的基本模式和结构。这种学习过程使模型能够捕捉数据的统计属性,从而生成具有类似特征的新样本。这一过程通常包括:
训练:模型在一个大型示例数据集(如文本、图像或音乐)上进行训练。在训练过程中,模型会学习数据中不同元素之间的统计关系,捕捉定义数据特征的模式和结构。
生成:训练完成后,模型可通过从所学分布中采样生成新内容。这包括从随机种子或输入开始,然后根据学习到的模式不断改进,直到产生令人满意的输出。
评估:生成的内容通常根据其质量、原创性以及与人工生成输出的相似性进行评估。这种评估可以是主观的,依赖于人类的判断,也可以是客观的,使用衡量生成内容特定属性的指标。
生成式人工智能模型的类型
目前已开发出各种类型的
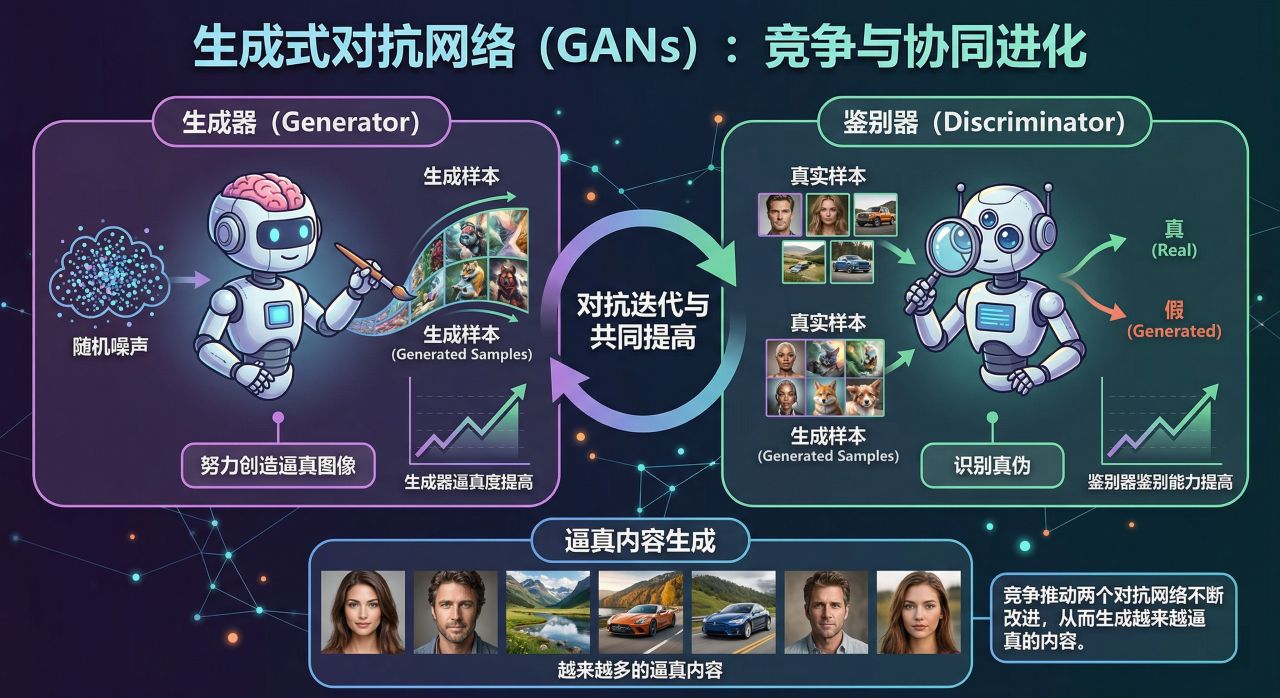
生成式人工智能模型,每种模型都有其优缺点:- 生成式对抗网络(GANs): GANs 由两个神经网络组成,一个是生成器,另一个是鉴别器,它们相互竞争。生成器创建新样本,而鉴别器则区分真实样本和生成样本。这种对抗过程会推动两个对抗网络不断改进,从而生成越来越逼真的内容。
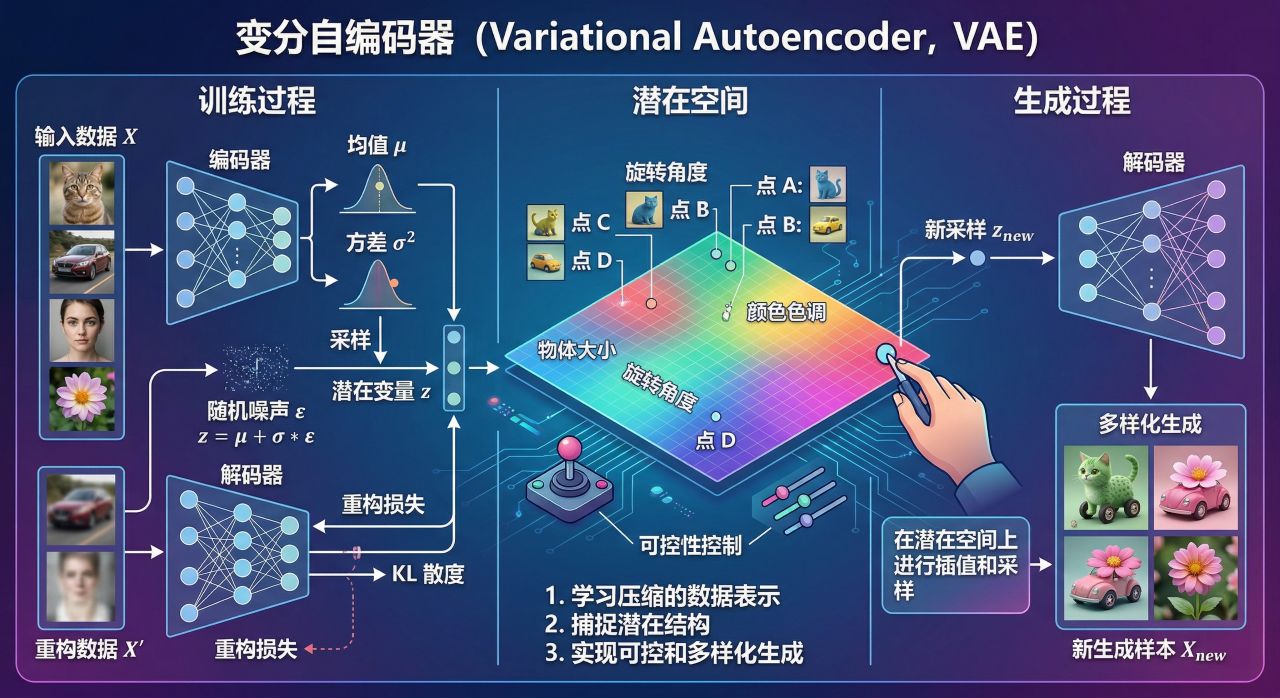
- 变分自编码器(Variational Autoencoder,VAEs):变分自编码器学习压缩的数据表示,并利用该表示生成新样本。它们在捕获数据的潜在结构方面特别有效,从而实现更加可控和多样化的生成。
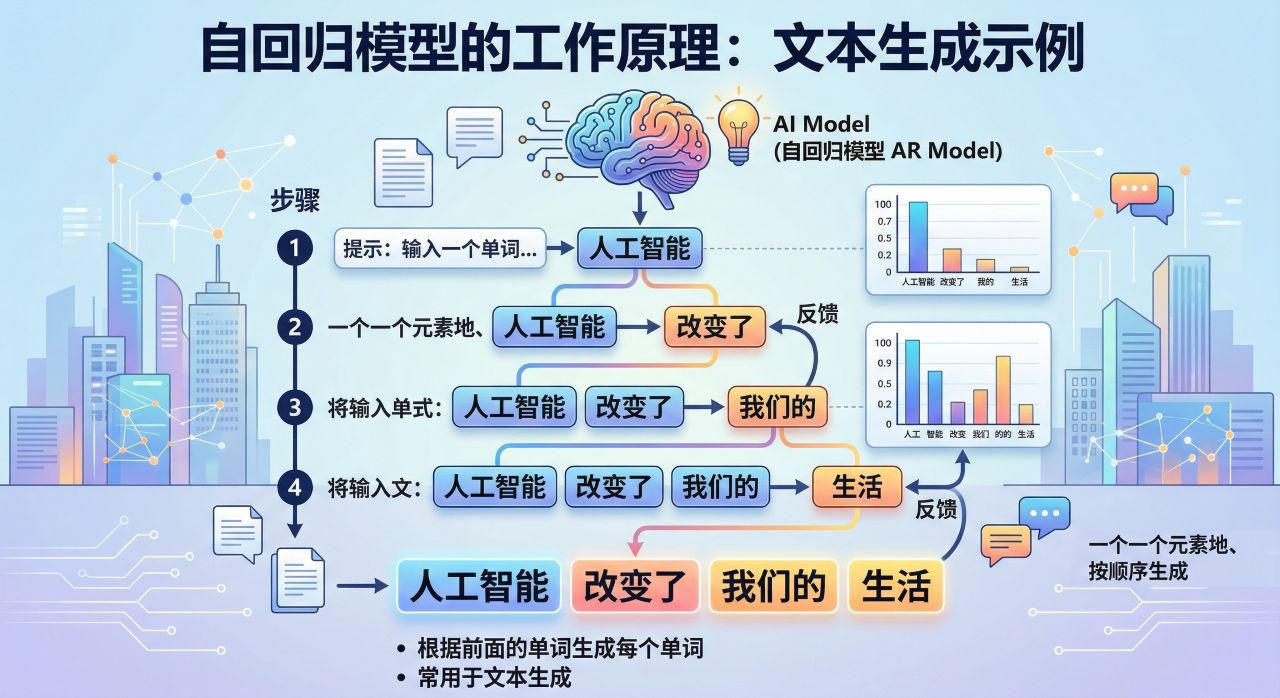
- 自回归模型: 这些模型根据前面的元素,一次生成一个元素,按顺序生成内容。它们通常用于文本生成,根据前面的单词生成每个单词。
- 扩散模型: 这个模型会逐渐向数据中添加噪音,直到数据变成纯噪音。然后,它们学会逆转这一过程,从噪声开始生成新样本,并对其进行改进。
重要的生成式人工智能概念
生成式人工智能涉及一系列独特的概念,这些概念对于理解这些模型如何学习、生成内容和进行评估非常重要。其中一些最重要的概念:
潜空间(Latent Space)也被称为潜特征空间或嵌入空间
latent space 是一种隐藏的数据表示,它以压缩的形式捕捉数据的基本特征和关系。把它想象成一张地图,在这张地图上,相似的数据点被聚拢在一起,而不相似的数据点则相距较远。像 变分自编码器 (VAEs) 这样的模型会学习 latent space,通过从这种压缩表示中采样来生成新内容。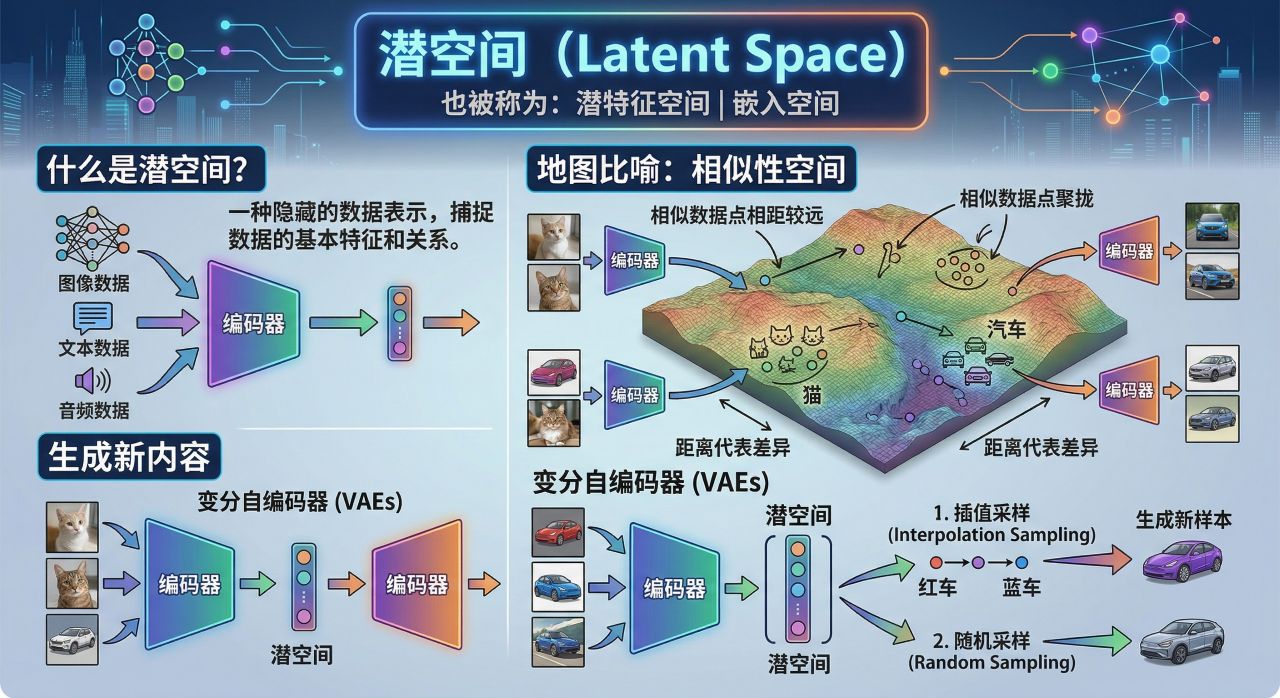
采样/取样 (Sampling)
采样是从已学分布中抽取生成新内容的过程。它包括为 latent Space中的变量选择值,然后将这些值映射到输出空间(例如,从 latent Space中的一个点生成图像)。生成内容的质量和多样性取决于模型学习底层分布的效率以及采样过程捕捉分布变化的程度。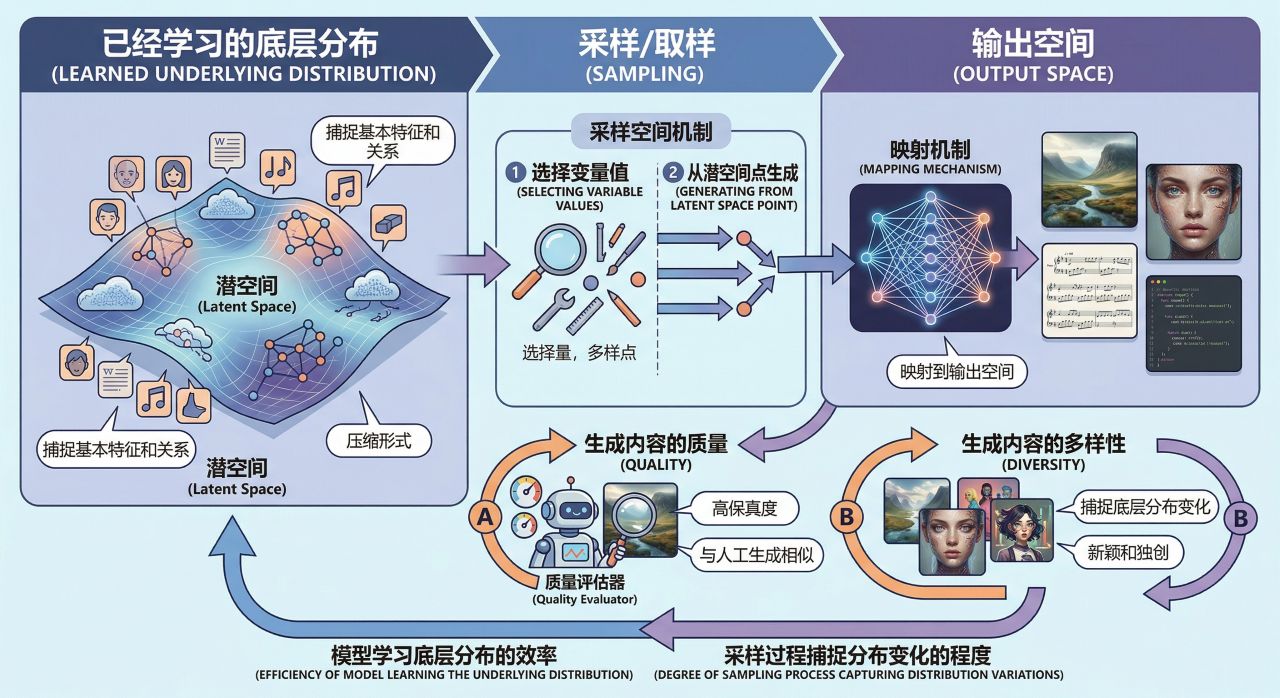
模式坍缩(Mode Collapse)
模式坍缩发生在生成器只学会生成有限种类的输出时,尽管训练数据可能包含更广泛的可能性。这可能导致生成的内容缺乏多样性,生成器被困在一种 "模式 "中,无法探索数据分布的其他模式。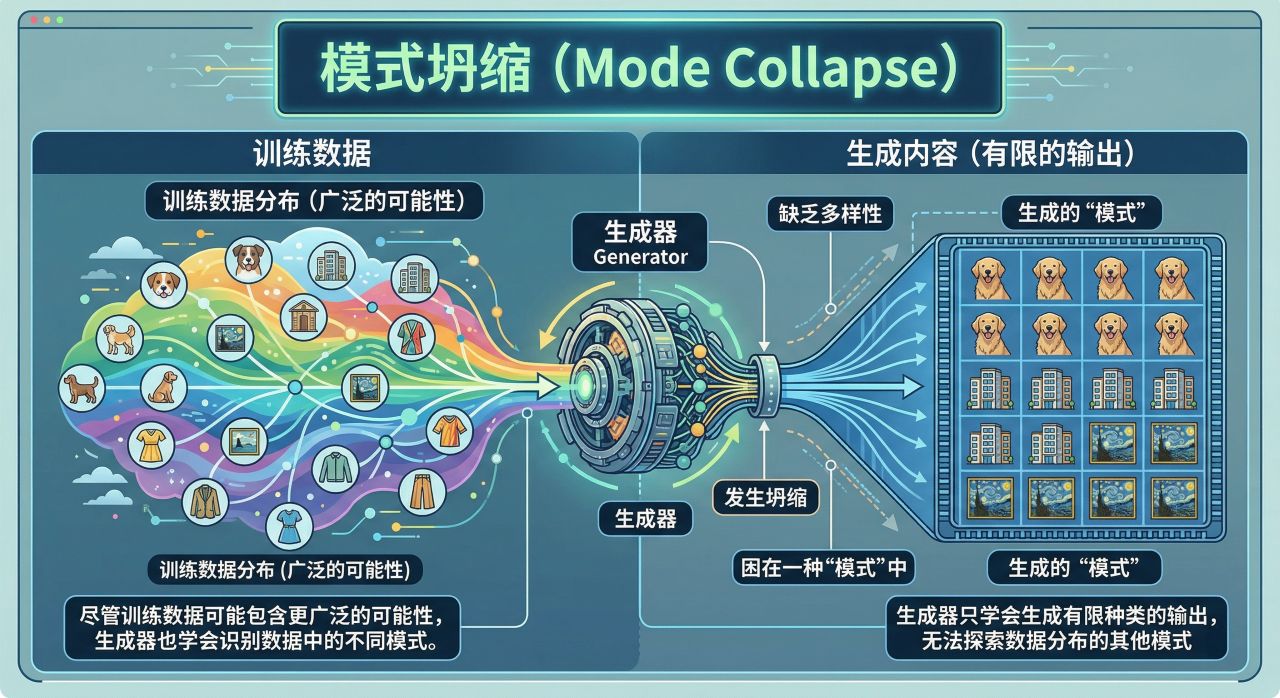
过拟合 (Overfitting)
过拟合是机器学习中的一个常见困扰,也适用于生成式人工智能 。当模型对训练数据的学习效果太好,甚至能捕捉到噪音和不相关的细节时,就会出现这种情况。这可能会导致泛化效果不佳,即模型难以生成与训练示例明显不同的新内容。在生成式人工智能中, 过拟合会限制模型的创造力和原创性。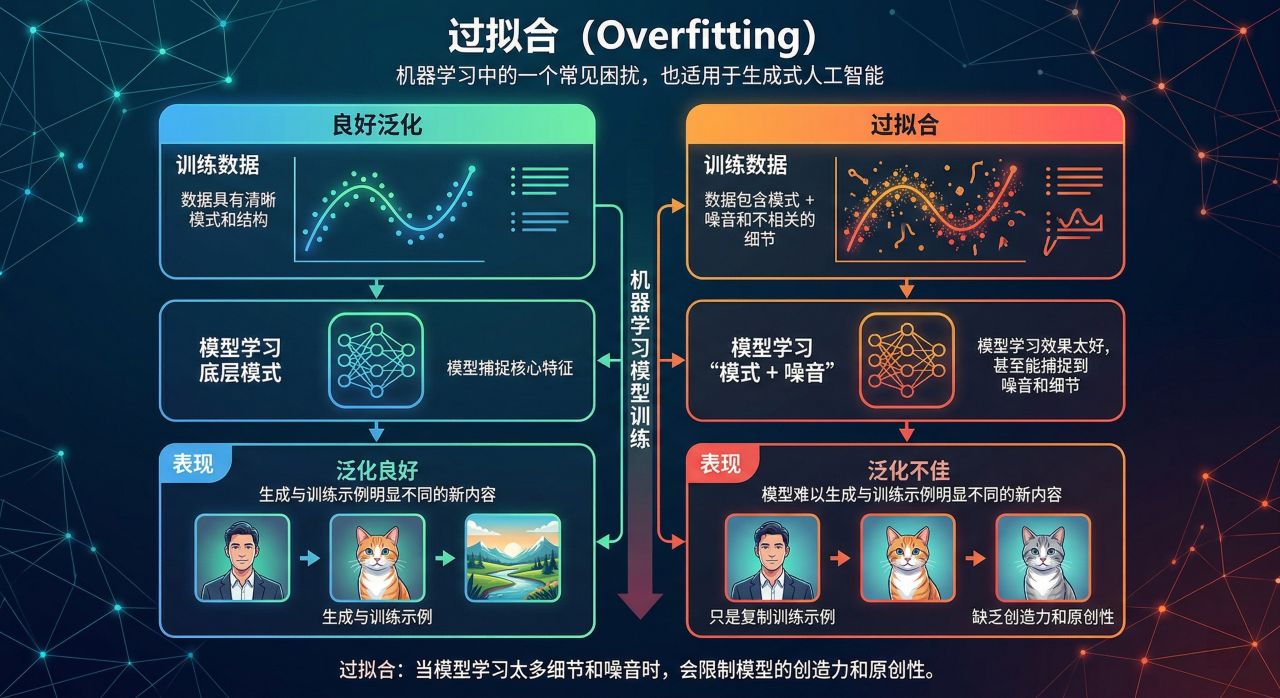
评估指标 (Evaluation Metrics)
在
生成式人工智能中,评估生成内容的质量和多样性至关重要。为此设计了各种指标,每种指标都侧重于生成输出的不同方面。一些常见的评估指标包括:初始分数 (IS):该分数通过评估图像的清晰度和预测类别的多样性来衡量生成图像的质量和多样性。
弗雷歇初始距离 Fréchet Inception Distance (FID):将生成图像的分布与真实图像的分布进行比较,FID 分数越低,表示相似度越高,质量越好。
BLEU(Bilingual Evaluation Understudy)评分:是通过与人工翻译的参考文本进行比较来评估机器翻译文本质量的指标 。 它量化了机器翻译输出与参考译文之间的相似度,分数越高表示质量越好。 从本质上讲,它衡量的是机器翻译的文本与参考译文在 n-grams (n 个单词的序列)方面的匹配程度。
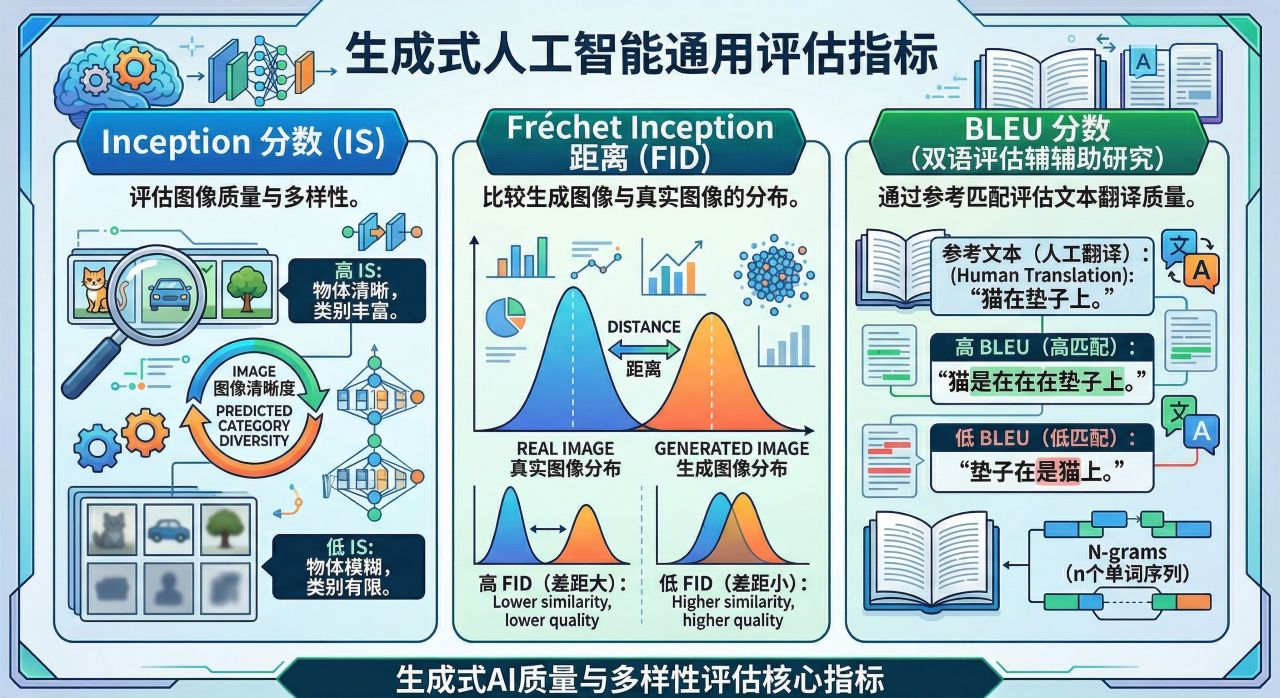
这些指标对生成内容的质量和多样性进行了量化评价,有助于研究人员、开发人员评估
Generative AI 模型 的性能,并进一步的改进。大语言模型
大语言模型 (LLMs)是一种人工智能(AI),近年来因其理解和生成类人文本的能力而备受关注。这些模型在海量文本数据的基础上进行训练,使它们能够学习语言中的模式和关系。这些知识使它们能够执行各种任务,包括翻译、总结、问题解答和创意写作。大语言模型(LLMs)通常基于一种名为Transformer的深度学习架构。Transformer特别适合处理文本等序列数据,因为它们能够捕获词汇之间的长距离依赖关系。这是通过自注意力机制实现的,该机制允许模型在处理句子时权衡句子中不同词汇的重要性。
LLMs 的训练过程包括向其输入大量文本数据并调整模型参数,以最大限度地减少其预测结果与实际文本之间的差异。这一过程的计算成本很高,需要专门的硬件,比如上万块
GPU 或 TPU。LLMs 通常具有三个特点:
大规模:LLM 的特点是规模巨大,通常包含数十亿甚至数万亿个参数。这种规模使它们能够捕捉人类语言的细微差别。
少量学习:LLM 只需几个示例就能完成新任务,这与需要大量标记数据集的传统机器学习模型不同。
上下文理解:LLM 可以理解对话或文本的上下文,从而生成更相关、更连贯的回复。
LLMs 如何工作
大语言模型是人工智能领域的一次重大飞跃,在理解和生成人类语言方面展示了极其强大的能力。要真正掌握它们的力量和潜力,探索驱动其功能的复杂技术非常重要。
基本概念说明
- Transformer 架构:并行处理整个句子的神经网络设计,与传统的 RNNs 相比,速度更快,效率更高。
- 分词 (Tokenization):将文本转换为称为
tokens的较小单位的过程,这些单位可以是单词、子词或字符。
- 编码器和解码器:转换器的组成部分,其中编码器处理输入文本以捕捉其含义,解码器根据编码器的输出生成输出文本。
- 自注意力机制 (Self-Attention Mechanism):计算词与词之间注意力分数的机制,使模型能够理解文本中的长距离依赖关系。
- 训练:LLMs 使用海量文本数据和
无监督学习进行训练,通过使用梯度下降来调整参数,以最小化预测误差。
Transformer 架构
大多数 LLMs 的核心是
Transformer 架构 ,这是一种彻底改变自然语言处理的神经网络设计。与按顺序处理文本的传统递归神经网络(RNNs)不同,Transformer可以并行处理整个句子,从而大大提高了速度和效率。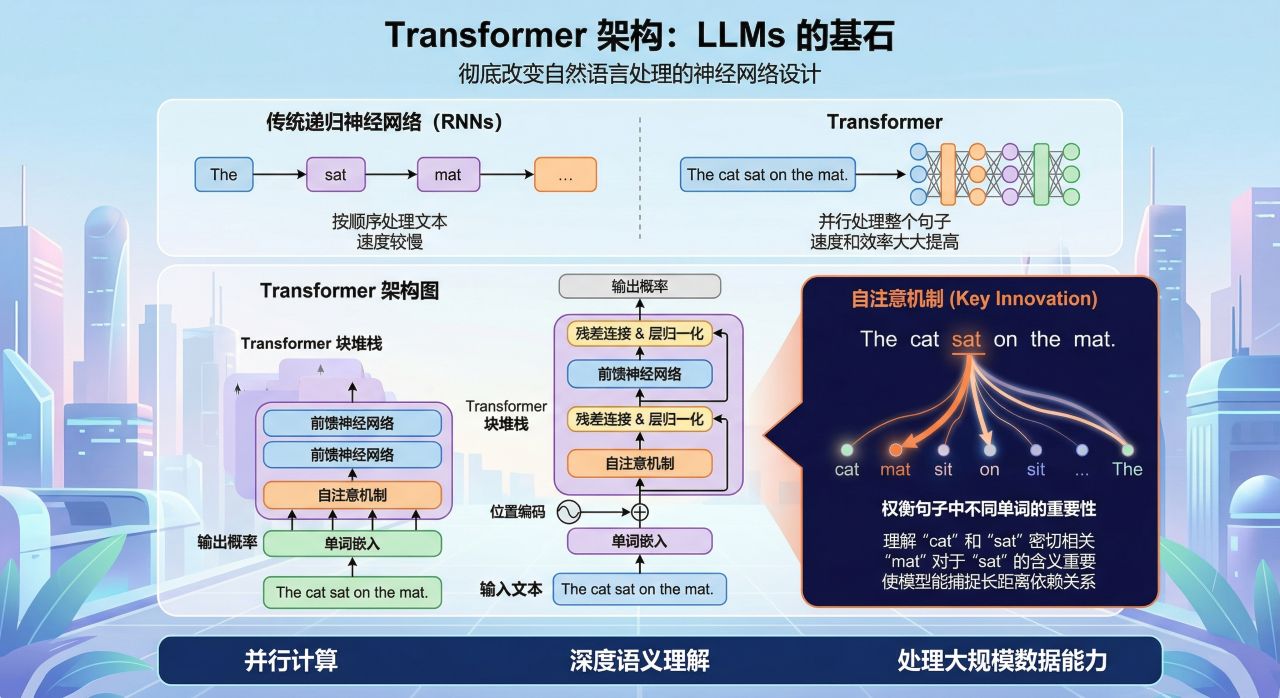
Transformer 的关键创新在于 自注意机制 。自注意机制 允许模型在处理句子时权衡句子中不同单词的重要性。想象一下,你正在阅读类似"The cat sat on the mat." 这样的句子。自注意机制 可以让模型理解 “cat” "和 "sat"是密切相关的,而 "mat"对于 "sat "的含义则不那么重要。分词:分解文本
在 LLMs 处理文本之前,需要将文本转换为模型可以理解的格式。这需要通过
分词来完成,在标记化过程中,文本被分解成更小的单元,称为 token 。 token 可以是单词、子词,甚至是字符,具体取决于特定的模型。例如,"I love artificial intelligence"这句话可以分词为
嵌入向量:将单词表示为向量
文本完成分词后,每个token会被转换为称为嵌入向量的数值表示。嵌入向量捕获词汇的语义含义,将其表示为高维空间中的点。具有相似含义的词汇在该空间中会拥有更加接近的嵌入向量。
例如,"国王 "和 "王后 "的嵌入向量比 "国王 "和 "桌子 "的嵌入向量更接近。
编码器和解码器处理和生成文本
Transformer由两个主要组件构成:编码器和解码器。编码器处理输入文本,捕获其含义以及词汇间的关系。解码器利用这些信息生成输出文本,例如翻译或摘要。
在 LLMs 中,编码器和解码器共同理解和生成类人文本。编码器处理输入文本,解码器根据编码器的输出生成文本。
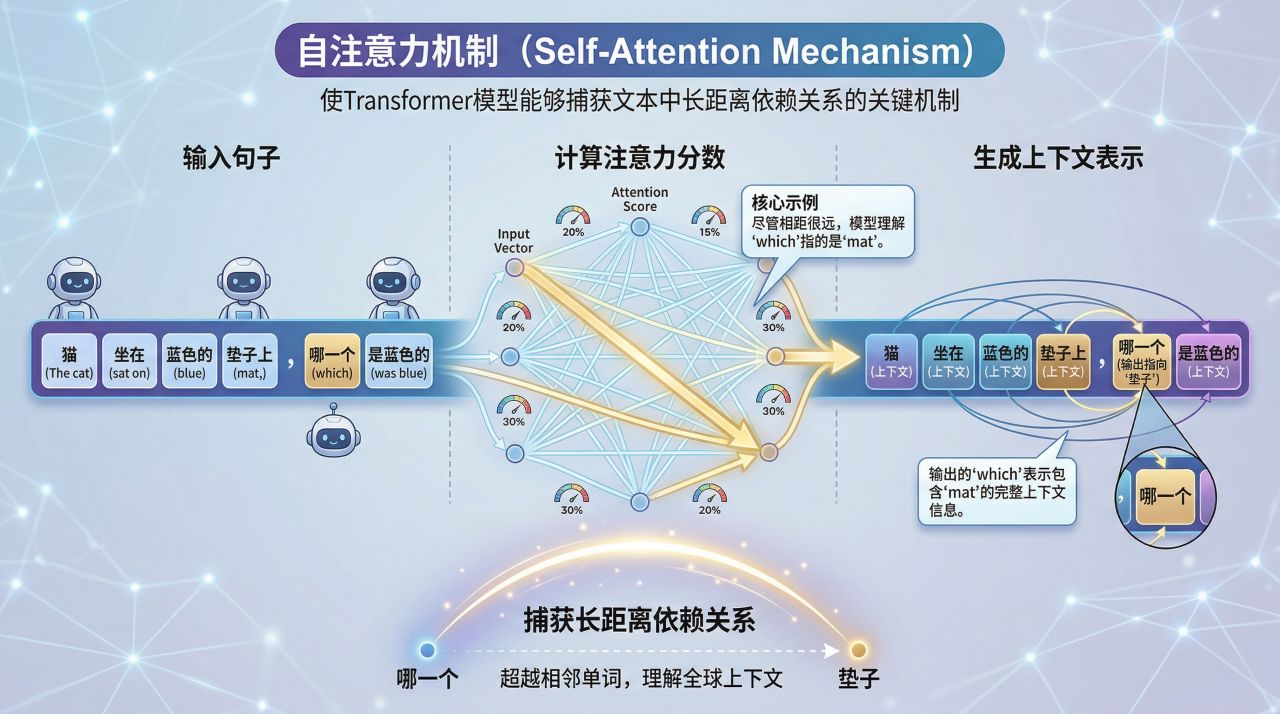
自注意力机制
自注意力机制是使Transformer模型能够捕获文本中长距离依赖关系的关键机制。它通过计算句子中每对词之间的注意力分数来工作。这些分数表示每个词应该在多大程度上"关注"其他词。
例如,在句子 “The cat sat on the mat, which was blue”(猫坐在蓝色的垫子上)中,尽管 "which "和 "mat "相差几个单词,但自注意力机制可以让模型理解 "which "指的是 “mat”。
训练 LLMs
LLMs 通常使用
无监督学习 ,在海量文本数据上进行训练。这意味着模型在没有明确标签或指令的情况下学习数据中的模式和关系。训练包括向模型输入文本数据并调整其参数,以尽量减小其预测结果与实际文本之间的差异。这通常使用
梯度下降的变体来完成,这是一种优化算法,通过反复调整模型参数来最小化损失函数。示例
假设我们想用 LLMs 生成一个关于猫的故事。我们会给模型提供一个提示,比如 “Once upon a time, there was a cat named Whiskers” (从前,有一只名叫Whiskers的猫)。然后,LLMs 将利用其语言和讲故事的知识,逐字生成故事的其余部分。
模型将考虑提示的上下文及其语法、句法和语义知识,生成连贯、引人注目的文本。它可能会生成以下内容
这只是一个简化的例子,但它说明了LLMs 如何根据给定的提示生成有创意的故事。